 ワンぱくジュリー調査団
ワンぱくジュリー調査団 

自分のPCで動作するローカルLLMの限界がどこにあるか調査した内容をまとめています。
調査方法は簡単でサイトにアクセスするだけ。
約9年前に購入した古いPCと新たに組んだPCで調査してみました。
以前、AI動画生成やローカルLLMを試すためにAI用PCを組みました。

構成の中心はRTX3090 24GBです。
これを元にマザボ・電源・メモリ・CPU・PCケースなど中古と新品をかき集めて組み上げました。
最新のハイスペPCからすれば見劣りするかもしれませんが、取り敢えず捻出できる金額で最善のものだと思っています。
ローカルAIではGPU性能も大事ですが、特に重要になるのがVRAM容量です。
モデルサイズが大きくなるほど必要なVRAMも増えるため、グラボ選びがかなり重要になります。
(これも技術の進歩でいずれ変わるのかな…)
ただ、スペック表を見ただけでは、
「このPCでどのAIモデルが動くのか」
「古いPCと新しいPCでどれくらい差があるのか」
「32Bや70Bクラスのモデルは現実的なのか」
ということが一目で分かりません。
そこで使ってみたのが、GIGAZINEさんで紹介されていた CanIRun.ai です。
CanIRun.aiは、ブラウザ上でPC構成を検出し、各AIモデルの動作可能性を表示してくれるサイトです。
公式サイトでも、GPU、CPU、RAMをブラウザ上で分析し、ローカルで実行できるAIモデルを調べるサイトとして説明されています。
では、私が所有している古いPCの GTX1080Ti と、新しく組んだAI用PCの RTX3090 で、どのくらい判定が変わるのかを比較してみましょう!
CanIRun.aiは、自分のPCでどのAIモデルが動きそうかを確認できるWebサイトです。
サイトにアクセスすると、GPU、VRAM、メモリ帯域、RAMなどをもとに、各モデルの動作目安を表示してくれます。
判定は以下のような段階で表示されます。
| ランク | 点数 | 表示 | 意味 |
|---|---|---|---|
| S | 100~85 | Runs great | 快適に動きそう |
| A | 84~70 | Runs well | 良好に動きそう |
| B | 69~55 | Decent | そこそこ動きそう |
| C | 54~40 | Tight fit | ギリギリ |
| D | 39~20 | Barely runs | かろうじて動く |
| F | 19~0 | Too heavy | 重すぎる |
今回比較したのは以下の2台です。
| 項目 | 旧PC | 新PC |
|---|---|---|
| グラボ | NVIDIA GeForce GTX1080Ti 11GB | MSI GeForce RTX3090 VENTUS 3X 24G OC |
| CPU | Intel Core i7-8700K | Intel Core i5-13500 |
| メモリ | DDR4-2666 16GB×4 計64GB | DDR4-3200 32GB×4 計128GB |
| 電源 | 850W 80PLUS GOLD | MSI MAG A850GL PCIE5 850W 80PLUS GOLD |
まずは、古いPCのGTX1080Tiです。

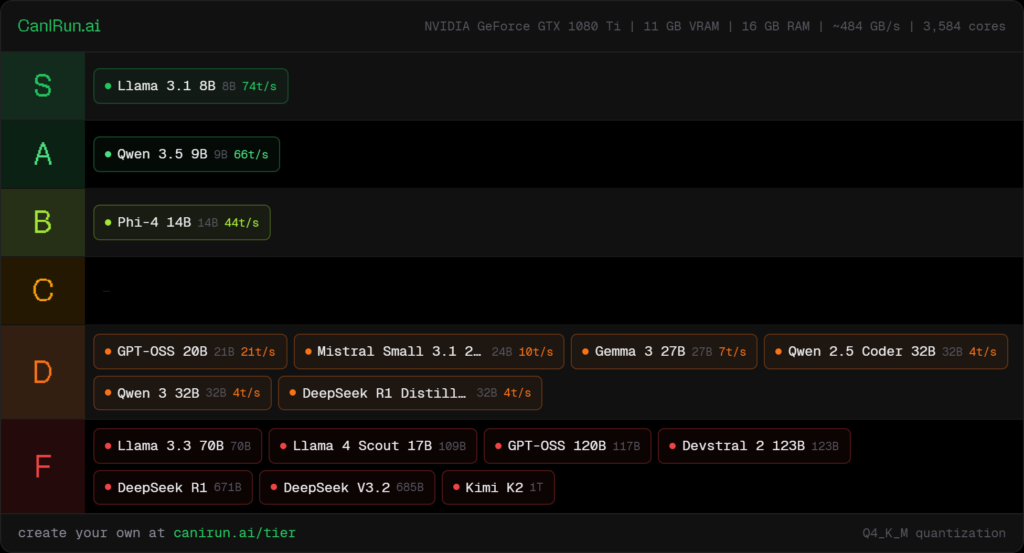
GTX1080Tiは古いグラボですが、VRAMは11GBあります。
そのため、小型〜中型のローカルLLMであれば、まだ意外と使えそうな結果になりました。
主なモデルの判定は以下です。
| モデル | 判定 | 推定速度 | スコア |
|---|---|---|---|
| Llama 3.1 8B | Runs great | 約74 tok/s | 85/100 |
| Qwen 3.5 9B | Runs well | 約66 tok/s | 81/100 |
| Phi-4 14B | Decent | 約44 tok/s | 64/100 |
| GPT-OSS 20B | Barely runs | 約21 tok/s | 30/100 |
| Mistral Small 3.1 24B | Barely runs | 約10 tok/s | 17/100 |
| Gemma 3 27B | Barely runs | 約7 tok/s | 13/100 |
| Qwen 2.5 Coder 32B | Barely runs | 約4 tok/s | 10/100 |
| Qwen 3 32B | Barely runs | 約4 tok/s | 10/100 |
| DeepSeek R1 Distill 32B | Barely runs | 約4 tok/s | 10/100 |
| Llama 3.3 70B | Too heavy | 0 tok/s | 0/100 |
結果を見ると、GTX1080Tiでも 8B〜9Bクラスはかなり現実的 です。
Llama 3.1 8BはRuns great、Qwen 3.5 9BはRuns wellという判定でした。
このあたりのモデルなら、古いPCでもローカルLLMを試すには十分候補に入ります。
Phi-4 14BもDecent判定なので、使えないわけではなさそうです。
ただし、余裕たっぷりというよりは「そこそこ使える」という位置づけです。
一方で、20Bを超えると一気に重くなります。
GPT-OSS 20BはBarely runs、32BクラスもBarely runsで、速度も約4 tok/s程度の表示でした。
実験として動かすことはできても、常用するにはストレスが出そうです。
70Bクラスになると、GTX1080TiではToo heavy判定でした。
次に新PCの結果です。
GPUはRTX3090、VRAMは24GBです。
CanIRun.aiでの判定は以下の通りでした。
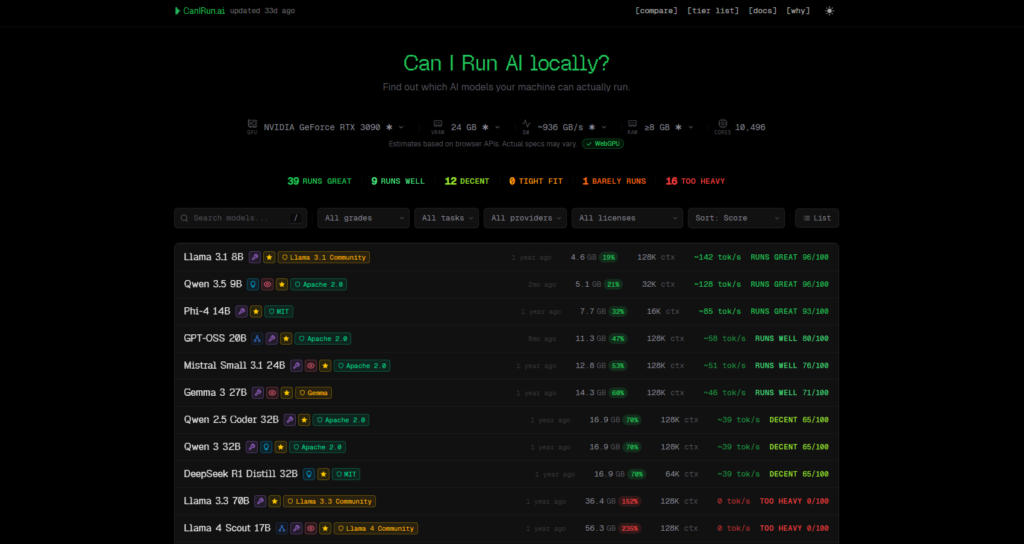
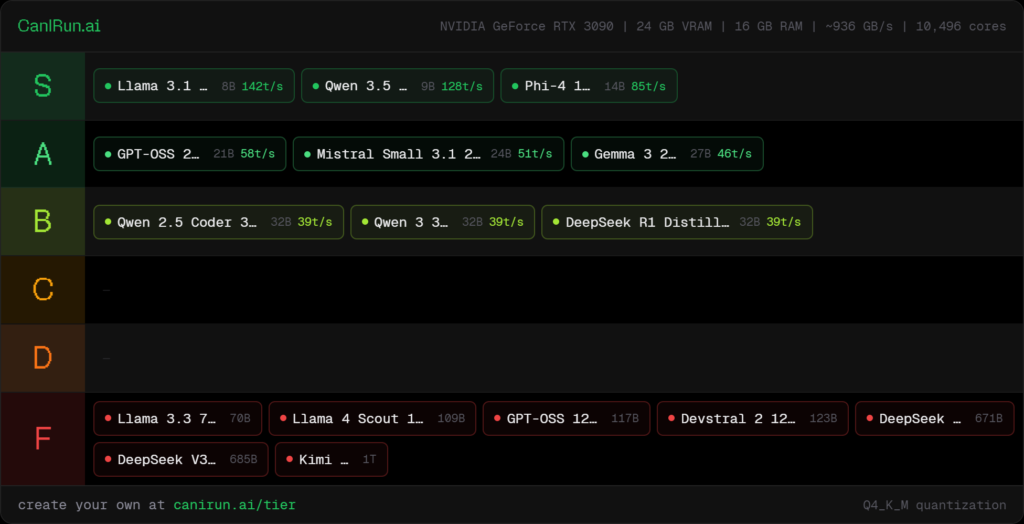
旧PCと比べると、Runs great、Runs well、Decentが大きく増えています。
主なモデルの判定は以下です。
| モデル | 判定 | 推定速度 | スコア |
|---|---|---|---|
| Llama 3.1 8B | Runs great | 約142 tok/s | 96/100 |
| Qwen 3.5 9B | Runs great | 約128 tok/s | 96/100 |
| Phi-4 14B | Runs great | 約85 tok/s | 93/100 |
| GPT-OSS 20B | Runs well | 約58 tok/s | 80/100 |
| Mistral Small 3.1 24B | Runs well | 約51 tok/s | 76/100 |
| Gemma 3 27B | Runs well | 約46 tok/s | 71/100 |
| Qwen 2.5 Coder 32B | Decent | 約39 tok/s | 65/100 |
| Qwen 3 32B | Decent | 約39 tok/s | 65/100 |
| DeepSeek R1 Distill 32B | Decent | 約39 tok/s | 65/100 |
| Llama 3.3 70B | Too heavy | 0 tok/s | 0/100 |
RTX3090になると、8B〜14Bクラスはかなり快適側に入ります。
旧PCではDecentだったPhi-4 14Bが、新PCではRuns greatになりました。
これはかなり大きい差です。
さらに、旧PCではBarely runsだった20B〜27Bクラスも、RTX3090ではRuns wellになっています。
32Bクラスも、旧PCではBarely runsでしたが、新PCではDecent判定になりました。
スコアも10/100から65/100まで上がっており、ローカルLLMとして試す現実味がかなり増しています。
モデルサイズ別に見ると、差が分かりやすいです。
| モデル規模 | GTX1080Ti | RTX3090 |
|---|---|---|
| 8B〜9B | 快適〜良好 | かなり快適 |
| 14B | そこそこ | 快適 |
| 20B〜27B | かなり重い | 実用圏内 |
| 32B | 厳しい | 試せる範囲 |
| 70B以上 | 厳しい | まだ厳しい |
RTX3090にしたことで、特に変わったのは 14B〜32Bクラス です。
GTX1080Tiでは、現実的に使うなら8B〜14Bあたりまでという印象でした。
RTX3090では、20B〜27Bクラスも実用圏内に入り、32Bクラスも試せそうな結果になりました。
逆に言うと、70BクラスはRTX3090でもまだ厳しいです。
Llama 3.3 70Bは、RTX3090でもToo heavy判定でした。
必要VRAMの目安も36.4GBと表示されており、24GBのRTX3090では収まりません。
RTX3090は強力ですが、70B以上を快適に動かすには、さらに大きなVRAMが必要になりそうです。
今回の結果を見る限り、GTX1080TiでもローカルLLMは一応使えます。
ただし、狙うモデルは絞った方が良さそうです。
現実的なのは以下のあたりです。
- Llama 3.1 8B
- Qwen 3.5 9B
- hi-4 14B
8B〜9Bクラスなら、古いPCでもかなり良い判定でした。
一方で、20B以上になると厳しくなります。
32Bクラスは動く可能性があっても、快適に使うにはかなり厳しそうです。
つまり、GTX1080Tiは「ローカルLLMを試す入口」としてはまだ使えます。
ただし、大きめのモデルを本格的に使いたいなら、VRAMの多いGPUが欲しくなります。
RTX3090にして良かった点は、選べるモデルの幅が広がったことです。
旧PCでは、8B〜14Bあたりが現実的な範囲でした。
新PCでは、20B〜27Bも使えそうで、32Bも試す候補に入ります。
ローカルLLMでは、モデルサイズが大きくなると回答品質や得意分野が変わることがあります。
もちろん、性能はモデルサイズだけで決まりません。
それでも、試せるモデルの選択肢が増えるのは大きなメリットです。
特にRTX3090は最新世代ではありませんが、24GB VRAM があるのが強みです。
ローカルLLM用途では、GPU世代やベンチマークスコアだけでなく、VRAM容量がかなり効いてくると感じました。
ただし、CanIRun.aiはとても便利ですが結果はあくまで推定です。
実際の動作は、以下の条件で変わります。
- 使用する実行環境
- 量子化方式
- コンテキスト長
- GPUドライバ
- CPU性能
- RAM容量
- 同時に起動しているアプリ
- モデルの形式
また、今回のスクリーンショットでも分かる通り、RAM表示は実機と違って見える場合があります。
CanIRun.aiの画面にも、ブラウザAPIによる推定であり、実際のスペックと異なる場合がある旨が表示されています。
そのため、CanIRun.aiは、「絶対にこの速度で動く」というより、
「自分のPCで、どのモデルが現実的かをざっくり確認する」
ためのサイトとして使うのが良さそうです。
今回は、CanIRun.aiを使って、旧PCのGTX1080Tiと、新しく組んだRTX3090のAI用PCを比較してみました。
結果として、GTX1080Tiでも8B〜9BクラスのローカルLLMはまだ現実的に使えそうです。
14Bクラスも、条件次第では候補に入ります。
ただし、20B以上になると一気に重くなり、32Bクラスは快適とは言いにくい結果でした。
一方、RTX3090 24GBでは、8B〜14Bクラスはかなり快適、20B〜27Bクラスも実用圏内、32Bクラスも試せそうな結果になりました。
特に、旧PCではBarely runsだったモデルが、新PCではRuns wellやDecentまで上がっている点は大きいです。
ローカルLLM用のPCを考えるなら、やはりVRAM容量はかなり重要です。
RTX3090は最新世代ではありませんが、24GB VRAMがあるためローカルLLM用途では今でも十分魅力があります。
今回CanIRun.aiで比較してみて、AI用PCを組んだ効果が数字として見えたのは面白かったです。
ローカルLLMに興味がある人やグラボの買い替えを考えている方は、一度CanIRun.aiで自分のPCを調べて参考にされてみても良いと思いました。
ということで今回はここまで!
見てくれてありがとね(・ω・)ノシ

